The Data Journey of Persistent Systems
Interview with Dr. Anand Deshpande, Founder, Chairman and Managing Director, Persistent Systems

Companies like Persistent Systems are the backbone of the data ecosystem in the country. After 30 years of advising companies in areas related to data on various fronts, Persistent has gathered a unique perspective on the data story of Pune. Dr. Anand Deshpande in conversation with the MCCIA team shares the inspiring journey of Persistent Systems and the unparalleled wisdom of a data veteran.

Can you tell us a little bit about Persistent and its long-standing association with data?
Data has been very close to our business. I have been in the data implementation business for the last 35 years now. I pursued my Ph.D. in database systems. Even before I returned to India to start Persistent, I was working very closely with data for several years. When we began our business, people were already anticipating the phenomenal growth in data. It was abundantly clear that Database Systems were the most ‘persistent’. This is where the name of the company emerged from — ‘systems and data that persist on the disk’.
We are in the business of helping software companies build products. In the last 30 years, we have helped several major database consultants, early-stage start-ups, and large-scale companies with data related systems.
How have data systems evolved in the last 30 years of Persistent?
In the early 90s, data was relevant primarily in the context of mainframes. Microprocessor-based systems, mini-computers, desktop workstations, and PCs had started to emerge. Most of them were single-unit machines. People were building data systems based on the relational model. A lot of activity was happening around object-oriented databases. Relational systems were proving to be ideal for commercial use. However, to store more complicated objects such as drawings, designs, and machine parts; better abstractions were required on the data front. This triggered the transformation into object databases.
In the mid-90s, another trend around data warehousing caught up. We took up several projects in the area. Then in the mid-2000s, big data became very important. During this time, we worked with companies to build big data systems.
In recent years we are living through the migration of data systems into the cloud.
With the advent of the internet, a lot of different data sets are getting stored. People are collecting large volumes of images, videos, and other forms of data as well. Storage and the ability to handle this kind of data is a new challenge.
Persistent has worked with product companies all through these generations. We have also worked with the users of data. There are a host of other issues besides storage in handling large-scale data. Identity, access, privileges, protection, privacy, and speed — these are only the tip of the pain points companies now need to investigate. We work with a large variety of customers who are interested in putting such data systems into their environment.

Can you discuss the capabilities of Persistent in the realm of data?
We have been working in areas such as data mining, machine learning, management of data, and predictive analysis for many years. We work on a combination of research and commercial projects. Persistent has customers with whom we build tools and solutions that are sold in the market. We aid with the deployment of these solutions by implementing machine learning algorithms in production. Persistent has always been extremely active in many of these data-related areas.
Could you tell us a bit about the Data Foundry initiative of Persistent?
If you look at data layers and the different number of products available today, creating a data integration environment is extremely complex. The number of choices of various kinds of systems available to get the same work done is abundant. We have preset a group of products and tools for this very purpose. Data foundry is aimed at minimizing the time spent in trying to figure out which product to use for which activity. It has pre-built solutions that can provide support for every need in both functional and non-functional departments.
Most people have data stored in different kinds of sources. There is a complexity involved in compiling data from various sources to a unified data lake. Data foundry addresses two sets of complexities. One is around the ability to bring data from diverse sources in one place. The second is around the ability to build a platform that allows for the compilation and integration of different products and helps in building implementable solutions.
Can you also speak briefly about the Manav Project in collaboration with NCCS and IISER?
We believe that biology is a big source of data. For India specifically, biological systems are an important area to invest in. There are a large number of students who study biology in India. Still, many of them do not have training and access to research material, papers, and other relevant information. The vision of Manav is to build a platform that will compile all the relevant biological data in one place.
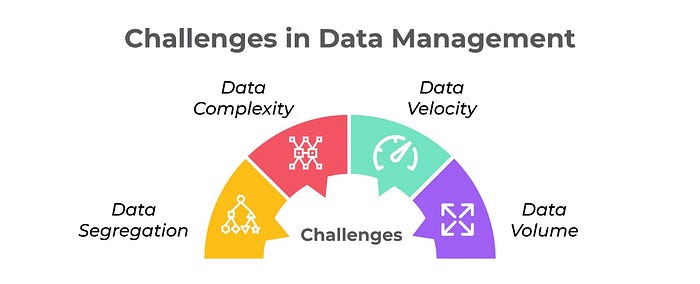
What are some challenges that clients and companies commonly face in managing their data pipeline?
From our experience in helping companies in data-centric domains, we have seen that the pain points can be jotted down as follows:-
Complexity: Modern datasets are incredibly diverse, and each of them has specific Meta information. Combing such multi-faceted data originating from different sources is very difficult.
Volume: The ability to handle vast amounts of data and extract meaning out of it is a crucial challenge.
Velocity: The need of the hour is not only to collect data in real-time but also to process it in real-time. Handling this velocity of data requires complex systems and a skilled workforce.
Segregation: When you have different kinds of data coming in from various sources, segregating and compiling it into common themes is critical.
In most data environments, the amount of effort required in collecting, cleaning, and processing data is quite strenuous. We strive to help businesses carry out these processes seamlessly.
How significantly can data mining improve processes for the industry?
If you want to make better decisions, your understanding of the data around you is hugely critical. Processed data can be instrumental in making meaningful decisions. If you build a system to manage and collect data, it ultimately ends up paying for itself with the vast improvements it can make in a business model.
As a nation, what do you think we must focus on in terms of data management? What are some significant projects carried out by Persistent in those areas of focus?
There is a growing opportunity for research in data. There is a lot of healthy activity taking place in data-related areas. Machine learning is entirely dependent on having the correct annotated data around. At a national level, we need to use data that is India-specific for such activities.
Persistent identified one such challenge in the realm of healthcare. Most data-sets critical for research in healthcare are generated in western countries. This results in the treatment of Indian patients with drugs and technologies developed for a different demographic. To tackle this, we took on a project in collaboration with Prashanti Cancer Care Centre in Pune. We are trying to collect India-specific DNA, RNA, and sequencing data for cancer patients.
Whether you take environmental, climate-related, or infrastructural data, it is extremely valuable to make nation-wide decisions regarding the investment of resources.
As a nation, we have to be deliberate enough about capturing and processing data in a centralized way. We must also focus on making this data publicly available to facilitate further research.
One can take any area imaginable, and there will be vast opportunities to make a meaningful difference with the innovative use of data. This holds true for Pune as well. Citywide data is critical in determining the kinds of tools and solutions appropriate for the residents.
Persistent has also collaborated with many research institutions in Pune. Can you tell us about that?
Data is not attractive to scientists. They want to focus on their research. Many a time, they struggle with getting their own data at the right place at the right time. So, this is the story that we tell most of the institutes we collaborate with — you do your science, we will do your data for you.
Since we are good at the data side of things, it is a win-win situation. With this insight, we have been working with many institutions in Pune, including IUCAA, IISER, NCRA, NCCS and many more. We are helping these institutes keep their data current and helpful for their science.
Having seen the city grow from the ground up, what would you say about the data story of Pune?
Pune has had a decent number of data-centric companies in the last few years, especially in areas of storage and cloud services. These are inherently hard skills to have, and Pune possesses a large number of them. We have a host of companies that are processing colossal amounts of data in their respective fields. Banks have now also jumped onto the bandwagon. Considering that we have a set of research labs, companies and academia — a collaboration between sources of data, collectors of data and companies like us who understand the science behind managing & processing large volumes of data is critical. If these three parties can work in tandem, there is a unique opportunity to further the science, research and product ecosystem of the city. It may not be the world leader yet, but the opportunities in Pune are humongous. If we manage to tap into it, there is hope for a meaningful change.
(This interview first appeared in the January 2021 edition of Sampada, the monthly magazine of MCCIA. You can read it here https://mcciapune.com/media/printmedia/January_2021_-_Web.pdf )
